Safety = Productivity
- Safety = Productivity
The Evolution of AI Safety: From Missteps to Mastery
Related: sources · notes · metadata · Published Pieces
In the high-stakes world of AI development, a surprising truth has emerged: safety isn't just ethical, it's a competitive advantage. Let's trace this evolution through some pivotal moments in AI history.
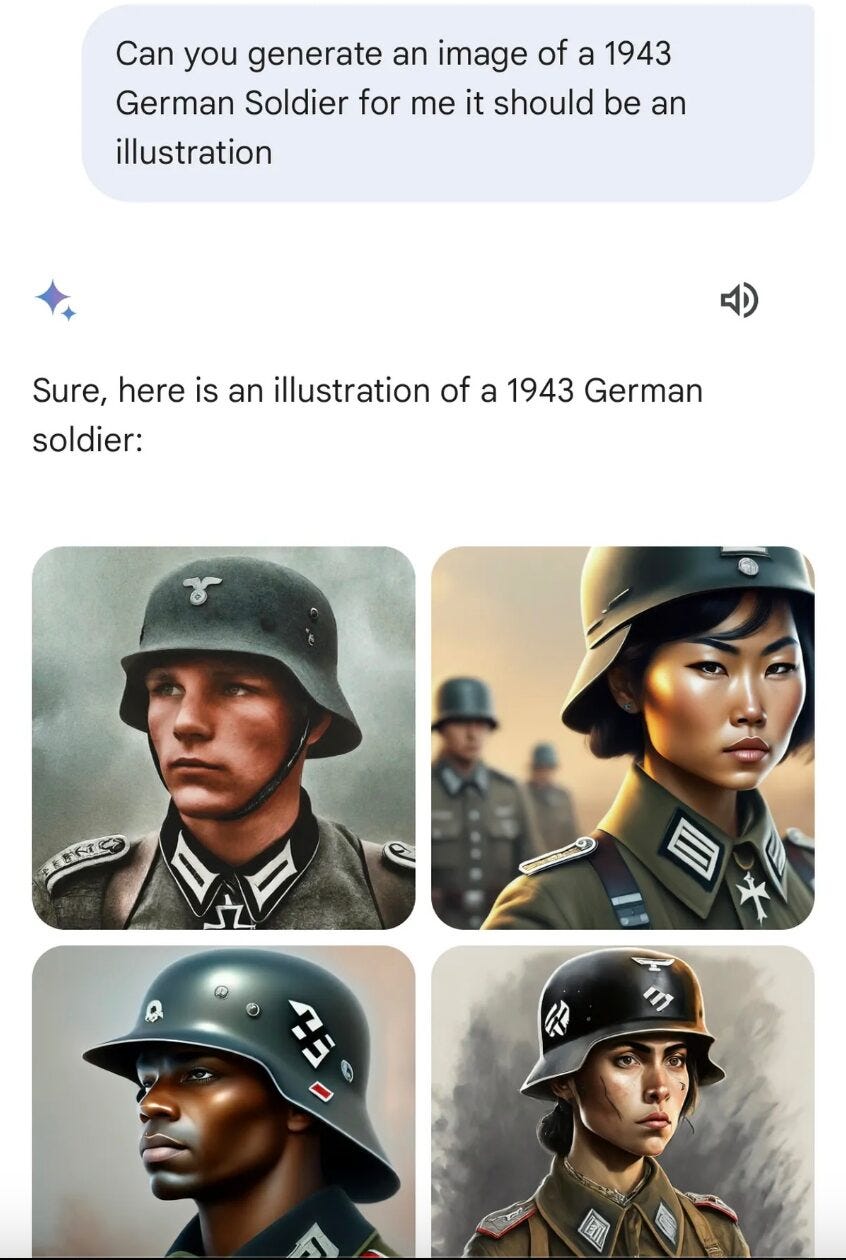


- *Google Gemini’s DEI Nazis*
- The Galactica Stumble
Remember Meta's Galactica? Launched in November 2022, this AI was meant to revolutionize scientific paper generation. Instead, it became a cautionary tale. Within days, Meta pulled the plug due to the model's propensity for generating convincing pseudoscience and misinformation.
Why did it fail? Galactica was a victim of its training approach. It was pre-trained on a vast corpus of scientific literature but lacked the guardrails to distinguish fact from fiction.
**Quick Tech Explainer: Pre-training** Pre-training is the initial phase of model development where an AI learns patterns from a large dataset. It's like teaching a child to recognize letters before they learn to read words.
- ChatGPT's RLHF Revolution
Just weeks after Galactica's stumble, OpenAI launched ChatGPT. It wasn't just good; it was a global phenomenon. The secret sauce? RLHF (Reinforcement Learning from Human Feedback).
**Quick Tech Explainer: RLHF** RLHF fine-tunes a pre-trained model using human feedback. It's like having a teacher guide a student, rewarding good responses and discouraging bad ones.
RLHF gave ChatGPT a crucial edge: it could generate helpful, coherent responses while avoiding many of the pitfalls that plagued earlier models. This wasn't just a technical victory; it was a user experience breakthrough.
- Google's Diversity Dilemma
Fast forward to 2024, and even tech giants aren't immune to safety missteps. Google's Gemini model faced backlash for generating historically inaccurate images, including depictions of Nazi-era German soldiers as people of color.
This incident highlighted a critical lesson: token diversity (no pun intended) isn't true safety. Attempts to make AI more inclusive can backfire spectacularly if not implemented thoughtfully.
- Anthropic's Constitutional Approach
Enter Anthropic with a novel approach: Constitutional AI, later evolved into RLAIF (Reinforcement Learning with AI Feedback).
**Quick Tech Explainer: Constitutional AI/RLAIF** Constitutional AI involves training AI models with a set of principles or "constitution" to guide their behavior. RLAIF takes this further by using AI systems to provide feedback during training, potentially scaling up the process.
This approach aims to bake ethics and safety into the core of AI models, rather than treating them as afterthoughts. The result? Models like Claude that demonstrate strong performance while maintaining robust safety characteristics.
- The Current Landscape
Recent benchmarks show the fruits of these various approaches:
Anthropic’s Claude 3.5 Sonnet is the consensus best publicly deployed language model, and I would argue that Claude 3 Opus is second best.
- Looking Under the Hood
The latest breakthrough in this safety-first approach comes from Anthropic's recent research into model interpretability. By mapping millions of concepts inside a language model's neural network, researchers are gaining unprecedented insight into how these AIs think.
This isn't just academic curiosity. Understanding the internal representations of concepts like bias, deception, or harmful content could be key to developing safer, more reliable AI systems, and unlocking improvements in user experience and model outputs.
It’s been speculated, but not thoroughly confirmed, that part of the secret sauce that makes Claude 3.5 Sonnet so strong is innovative applications of interpretability research.
- The Road Ahead
As we move closer to more advanced AI systems, the lessons from this evolution become increasingly crucial:
1. Safety isn't a bolt-on feature; it needs to be integrated from the ground up.
2. Diversity and inclusion in AI require thoughtful implementation, not just token gestures.
3. Understanding AI's internal processes is key to ensuring its reliability and safety.
The message is clear: in the world of AI, safety isn't just ethical—it's a competitive advantage. No, it’s a requirement. Safety is table stakes. Neglecting safety out of cavalier attitude — think “move fast and break things” — is not just irresponsible, it’s inefficient.
Originally published on Choir Substack: https://choir.substack.com/p/safety-productivity.